TextSnatcher is a free and open source OCR application for Linux. Using TextSnatcher you can copy any text from image, pdf, website, videos and save in your clipboard. Actually it takes the screenshot of the website, video and pdf and converts to text. It is based on popular Tesseract OCR Engine. Currently it supports English, Thai, Tamil, Japanese, Hindi, Arabic, Russian, French, Chinese(Simplified), Spanish languages. It is released under GNU General Public License v3.0.
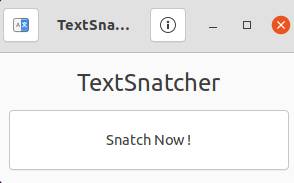
Install TextSnatcher on Ubuntu
TextSnatcher is available as flatpak package from flathub. First install flatpak and flathub on your system and restart it. After that in the terminal run below TextSnatcher flatpak installation command. It will install the latest version of TextSnatcher.
flatpak install flathub com.github.rajsolai.textsnatcher
After the installation you can run the app using below command or via application menu.
flatpak run com.github.rajsolai.textsnatcher
Just click the Snatch Now button. It will open the screenshot tool. Take the screenshot of the text. Now click the the share button. It will convert the image into text in your clipboard. Now paste the text in your text edit application. That’s it.
You can also uninstall it via
sudo flatpak uninstall com.github.rajsolai.textsnatcher
That’s it





Pingback: Frog – Extract Text From Image Video QR Code | CONNECTwww.com