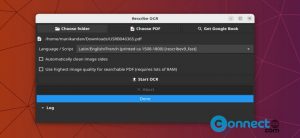
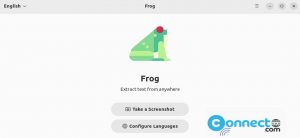
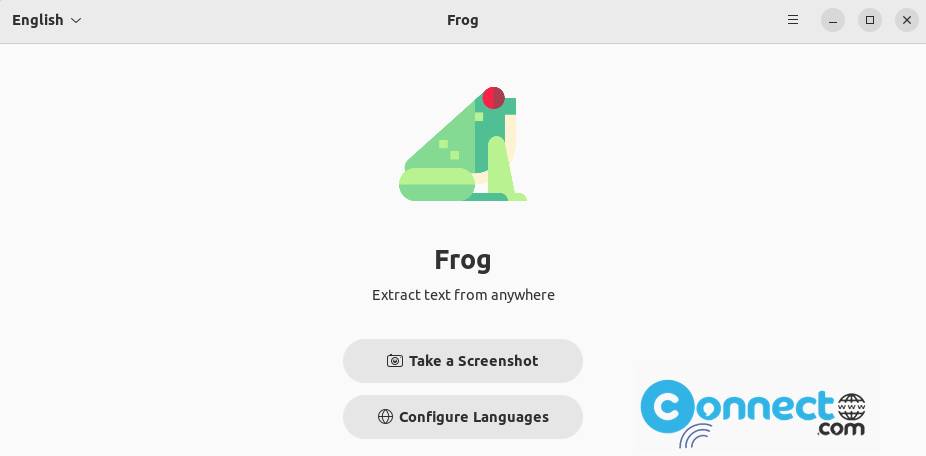
Free-OCR http://www.free-ocr.com/ is a free online OCR tool.This site helps to extract text from image.No registration necessary to use this service and completely free.Free-OCR supports JPG, GIF, TIFF BMP or PDF file formats and Bulgarian, Catalan, Czech, Danish, Dutch, English, Finnish, French, German, Greek, Hungarian, Indonesian, Italian, Latvian, Lithuanian, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovene, Spanish, Swedish, Tagalog, Turkish, Ukrainian, Vietnamese languages.
Images must not be larger than 2MB, no wider or higher than 5000 pixels and 10 image uploads per hour.
(more…)